微调 SDK 教程
1. 功能概览
潞晨云微调 SDK 是一款面向 Post-training(后训练) 时代的 Serverless 开发工具。它兼容 Tinker 范式,支持从监督微调 (SFT) 到复杂强化学习 (RL) 的全链路开发, 旨在为开发者提供灵活、高效的大模型微调体验。该 SDK 基于 Thinking Machines Lab 开源的 Tinker 项目 https://github.com/thinking-machines-lab/tinker(Apache License 2.0)进行开发。我们感谢开源社区的贡献,并在此基础上针对潞晨云的云基础设施进行了深度定制。通过将繁重的计算负载卸载至云端高性能集群(HPC),微调 SDK 在保障本地开发灵活性的同时,实现了高效的微调流程。
核心优势:
- 本地逻辑,云端执行:您可以在本地编写训练循环、调试数据处理逻辑,而梯度计算与参数更新则在远程服务器上高效完成。
- 细粒度控制:支持 forward、backward 和 optim_step 等原子级操作,让您像编写 PyTorch 原生代码一样控制训练流程。
- 全栈支持:原生支持 SFT 到 PPO、GRPO、DPO 等 RL 算法,内置对主流模型(如 Qwen 系列)和 LoRA 微调技术的完整支持
- 按 Token 计费: 仅对 Prefill/Sample/Train 的有效计算收费,环境配置与调试环境 0 费用
2. 准备工作
在开始之前,请确保您已完成环境配置及鉴权设置,具体操作请参考以下步骤:
2.1 获取 API 密钥
为了建立与高性能计算集群的安全连接,您需要获取专属的 API Key:
- 登录潞晨云控制台。
- 点击秘钥 > 创建API秘钥 即可 生成API密钥。
- 注意:请妥善保管 API Key ,切勿在公开代码库中泄露。
2.2 安装 SDK
您需要安装基础 SDK 及配套工具。目前支持通过源码或 pip 安装:
# 克隆仓库并安装
pip install hpcai
3. Quick Start:构建您的第一个微调任务
本教程将演示如何在潞晨云上使用微调 SDK,基于 LoRA 技术对 Qwen3-8B 模型进行监督微调(SFT)。
步骤 1:初始化客户端
首先,配置连接端点并初始化服务客户端。
请注意:Base URL 可公开,是连接潞晨云机器的 URL;API KEY 不可公开,每个用户有单独的 API KEY,用于校验。
import time
import hpcai
from hpcai import types
import wandb
from pathlib import Path
import datasets
from datasets import concatenate_datasets
from hpcai.cookbook import renderers
from hpcai.cookbook.data import conversation_to_datum
from hpcai import checkpoint_utils
BASE_URL = "https://cloud.luchentech.com/finetunesdk" # 连接潞晨云机器的 URL
API_KEY = "Your_API_Key_Here" # 实例化服务客户端
service_client = hpcai.ServiceClient(base_url=BASE_URL, api_key=API_KEY)
步骤 2:创建训练实例
定义模型参数并创建远程训练实例。潞晨云 SDK 支持通过简单的配置开启 LoRA 微调。
MODEL_NAME = 'Qwen/Qwen3-8B'
LORA_RANK = 32# 创建 LoRA 训练客户端,这一步会在云端初始化模型资源
training_client = service_client.create_lora_training_client(
base_model=MODEL_NAME,
rank=LORA_RANK,
)
print(f"Training session started with Model ID: {training_client.model_id}")
步骤 3:数据准备与处理
利用 SDK 提供的 Tokenizer 处理数据集。本例使用 "Knights and Knaves" 数据集。
# 获取与远程模型匹配的 Tokenizer
tokenizer = training_client.get_tokenizer()
# 加载并预处理数据
dataset = datasets.load_dataset("K-and-K/knights-and-knaves", "train")
dataset = concatenate_datasets([dataset[k] for k in dataset.keys()]).shuffle(seed=42)
# 格式化数据结构
dataset = dataset.map(
lambda example: {"messages": [
{"role": "user", "content": example["quiz"]},
{"role": "assistant", "content": example["solution_text"]},
]}
)
步骤 4:执行训练循环
这是 SDK 最具特色的部分。通过 forward_backward 和 optim_step 驱动云端训练, 您可以完全掌控训练的每一步(前向传播、反向传播、优化器更新)。
# 超参数配置
BATCH_SIZE = 32
LEARNING_RATE = 1e-4
MAX_LENGTH = 1024
TRAIN_STEPS = 30
SAVE_EVERY = 30
LOG_PATH = "./tmp/tinker-examples/sl-loop"# 初始化 WandB 监控(可选)
wandb.init(project='qwen-3-8B-sft-demo')
target_steps = min(len(dataset) // BATCH_SIZE, TRAIN_STEPS)
renderer = renderers.get_renderer("role_colon", tokenizer)
print("Starting training loop...")
for step in range(target_steps):
start_time = time.time()
# 1. 检查点保存逻辑if step > 0 and step % SAVE_EVERY == 0:
paths = await checkpoint_utils.save_checkpoint_async(
training_client, name=f"step_{step}", log_path=LOG_PATH,
loop_state={"step": step}, kind="both"
)
print(f"Checkpoint saved: {paths}")
# 2. 准备批次数据
batch_start = step * BATCH_SIZE
batch_rows = dataset.select(range(batch_start, batch_start + BATCH_SIZE))
batch = [
conversation_to_datum(
row["messages"], renderer, MAX_LENGTH,
renderers.TrainOnWhat.ALL_ASSISTANT_MESSAGES
) for row in batch_rows
]
# 3. 远程执行前向与反向传播 (Forward + Backward)
fwd_bwd = training_client.forward_backward(batch, loss_fn="cross_entropy")
# 4. 学习率调度与优化器步进 (Optim Step)
lr = LEARNING_RATE * (1.0 - step / target_steps)
optim = training_client.optim_step(types.AdamParams(learning_rate=lr))
# 5. 获取结果与指标
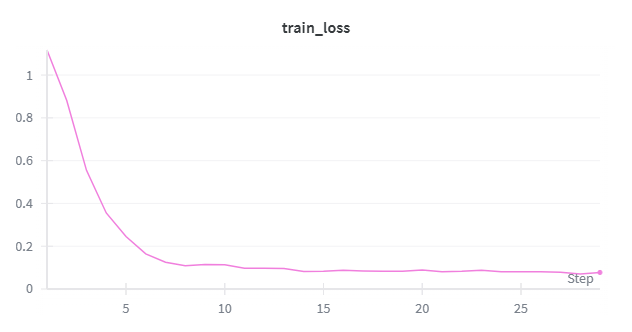
result = fwd_bwd.result()
loss = result.metrics.get("loss:mean", 0.0)
# 打印进度
elapsed = time.time() - start_time
print(f"Step {step + 1}/{target_steps} | Loss: {loss:.4f} | LR: {lr:.2e} | Time: {elapsed:.2f}s")
wandb.log({'train_loss': loss}, step=step+1)
步骤 5:资源释放
训练完成后,请释放云端 GPU 资源。
# 释放模型资源
training_client.unload_model().result()
print("Model unloaded successfully.")
4. 进阶教程:RL实践 与 最佳实践Cookbook
潞晨云官方Cookbook 提供了更多兼容Tinker的开箱即用的教程, 以下我们将利用强化学习(RL)对 Qwen-4B 模型进行微调,提升其在 GSM8K(小学数学) 数据集上的推理能力。
核心逻辑
-
train.py(Entry Point): 初始化 TrainingClient,解析配置参数 (Hydra/Argparse),编排RL 训练循环。 -
math_env.py(RL环境定义) : 封装 GSM8K 数据加载逻辑,负责构建Prompt和管理环境状态交互。 -
math_grading.py(奖励函数): 实现后处理逻辑,负责解析模型输出并计算 Reward 信号(与Ground Truth 比对), 以驱动策略优化。
# 环境准备
pip install hpcai
# 进入目录
cd HPC-AI-SDK/src/hpcai/cookbook/recipes/math_rl
# 启动训练,请根据你的实际情况替换 api_key 和其他参数。
python train.py \
base_url="https://cloud.luchentech.com/finetunesdk" \
api_key="Your_API_Key_Here" \
model_name=Qwen/Qwen3-4B \
env=gsm8k \
learning_rate=1e-6 \
groups_per_batch=2 \
lora_rank=64 \
eval_every=20 \
save_every=20 \
wandb_project=cookbook_math_rl
关键参数解读
-
env=gsm8k: 指定训练环境为复杂的应用题场景 -
lora_rank=64: LoRA 微调的参数量,数值越大拟合能力越强,显存占用越高 -
base_url/api_key: 连接训练集群的认证信息,请替换为你的实际 Key
点击查看更多Cookbook示例:https://github.com/hpcaitech/HPC-AI-SDK/tree/cookbook